Observability Challenges with Kubernetes
Kubernetes can be a particularly challenging data source to manage. the transient and ephemeral nature makes the collection of observability metrics quite difficult. Furthermore, platform administrators frequently lack control over the specific logging configurations of each application within Kubernetes. These applications often generate complex events that create high volumes of data sent to the SIEM or logging platform. This leads to expensive increases in licensing and inefficient allocation of manpower to analyze data that doesn’t always provide significant value.
Cribl Edge and Kubernetes, a Perfect Match
While there are many tools that can be used to collect Kubernetes logs and metrics, installing, configuring, and maintaining them requires additional resources and IT costs. Moreover, these products introduce an additional layer of complexity as they lack visibility into the events occurring at the source level.
Cribl Edge is the perfect solution for monitoring Kubernetes data. Using Edge reduces the complexity of your tech stack by unifying collection and processing into a single tool. Instead of relying on a distinct tool for data ingestion, and then processing before sending to its ultimate destination.Why Cribl Edge for Kubernetes:
- Helm charts allow for quick and easy deployments of Cribl Edge
- Collect data at the actual source
- Deploy in cluster to collect the right amount of logs and metrics
- Capture console logs from containerized applications
- Capture metrics with enhanced metadata
- Filter rules allow you to easily filter out the data you do not want
Making use of native functionality in Cribl Edge can provide additional benefits like optimizing metric output, reducing log/alert fatigue, and facilitating troubleshooting of issues.
Now that you know some of the benefits of using Cribl Edge and Kubernetes together, let's take a look at a specific use-case.
Monitoring Kubernetes Metrics with the Sampling Function
There are several Kubernetes metrics that can be monitored:
- Kubernetes cluster metrics
- Control plane metrics
- Kubernetes node Metrics
- Pod Metrics
- Application metrics
Many of the metrics produced by Kubernetes pertain to the same cluster, but from different perspectives or levels of depth. This makes them the ideal candidate to leverage reduction techniques while also maintaining the fidelity necessary for troubleshooting. Using Cribl Edge’s Sampling Function provides greater control over output than other solutions, like Filter Expressions or even increasing the polling interval.
Let's walk through a simple use case involving monitoring memory.
Use Case: You are receiving Out Of Memory (OOM) errors due to a pod utilizing more memory than anticipated. To optimize node status output concerning memory, and reduce less critical information while still powering dashboards and alerts, leverage the sampling function. Sample the ‘kube_node_status_condition’ where the condition ‘MemoryPressure’ is false.
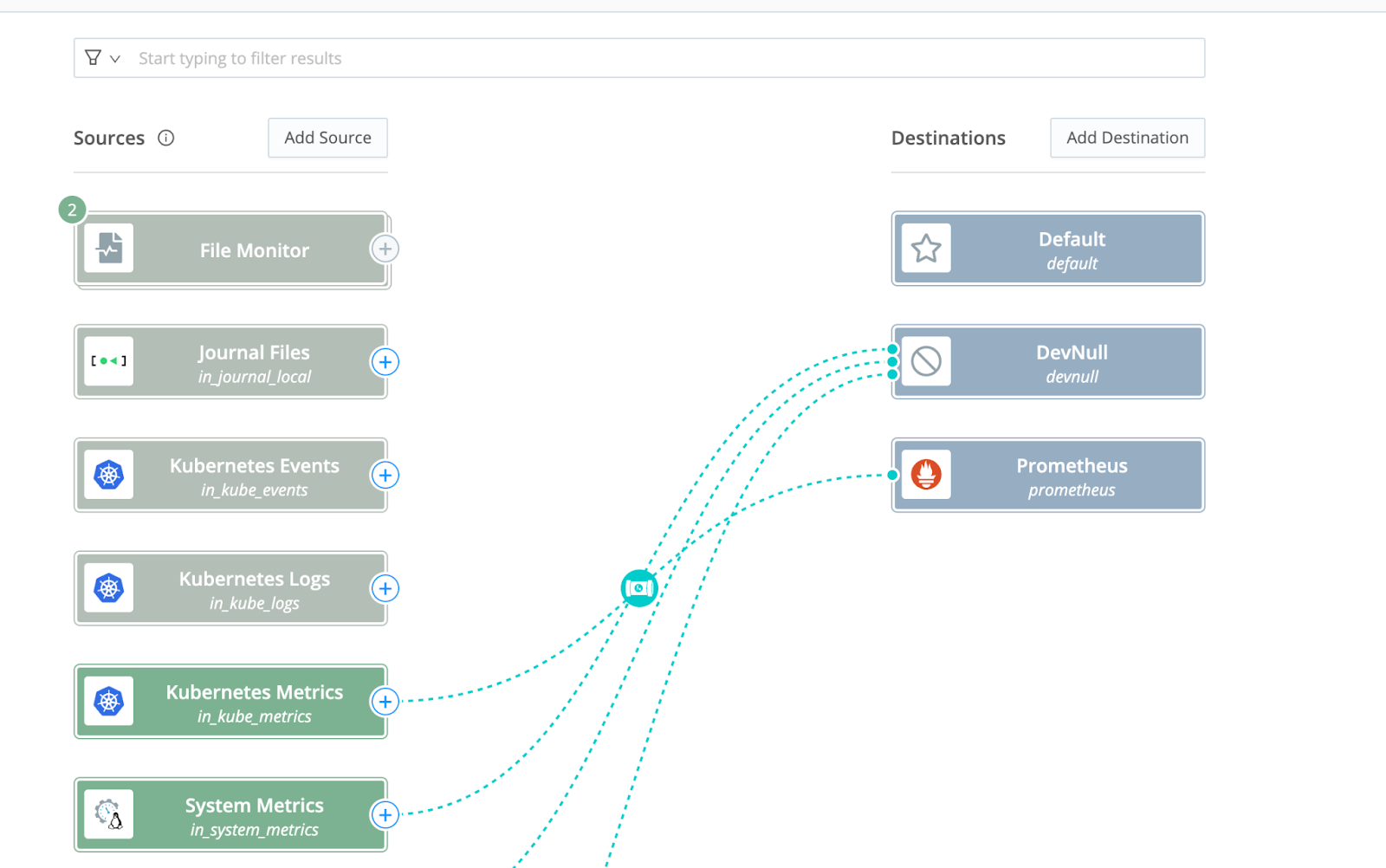
Step 1: Add Source and Destination -> Create a Pipeline to work with
First, make sure you have the source and destination of choice configured. Then, create or select the route between the source and the destination of choice.
Manage -> Fleet -> Collect
In our example, you will be working with the Kubernetes Metrics source which are kube-state-metrics. This data provides live information about the resource utilization of objects like pods, nodes, and deployments at the highest level.
You will use Prometheus as the destination since the output schema is based on the Prometheus format, but any supported destination can be used.
Pro TIP: Other metric sources, such as cAdvisor, provide low-level stats from containers (e.g., RAM and CPU usage) and can also provide valuable insights. It’s easy to collect this information with the Prometheus Edge Scraper source.
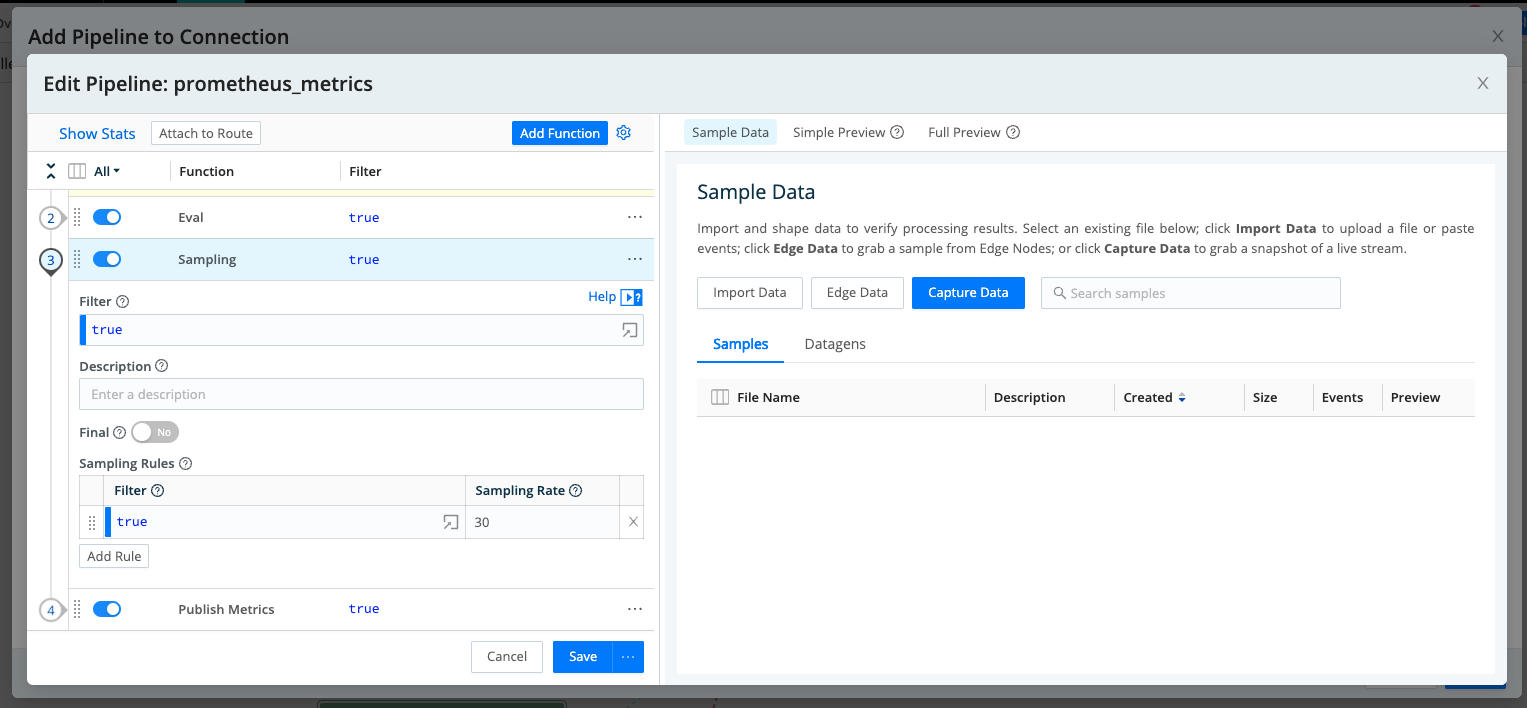
Step 2: Add the Sampling Function, and Modify the Sampling Rate
Once you have created or selected the pipeline, add the Sampling Function to your Route. change our Sample Rate from 1 to 30 so that we can begin to understand how this function will impact our results.
Pipeline -> Add Function -> Search for Sampling
Leaving the filter set to ‘true’ allows all events to pass through the filter, but since you have set the Sampling Rate to 30, the output will be 1 event of every 30 passing through the filter. However, increasing the Sampling Rate does not increase the fidelity of the output, and likely decreases it because we are sampling both critical and non-critical metrics. Continue to see how you can get the best results.
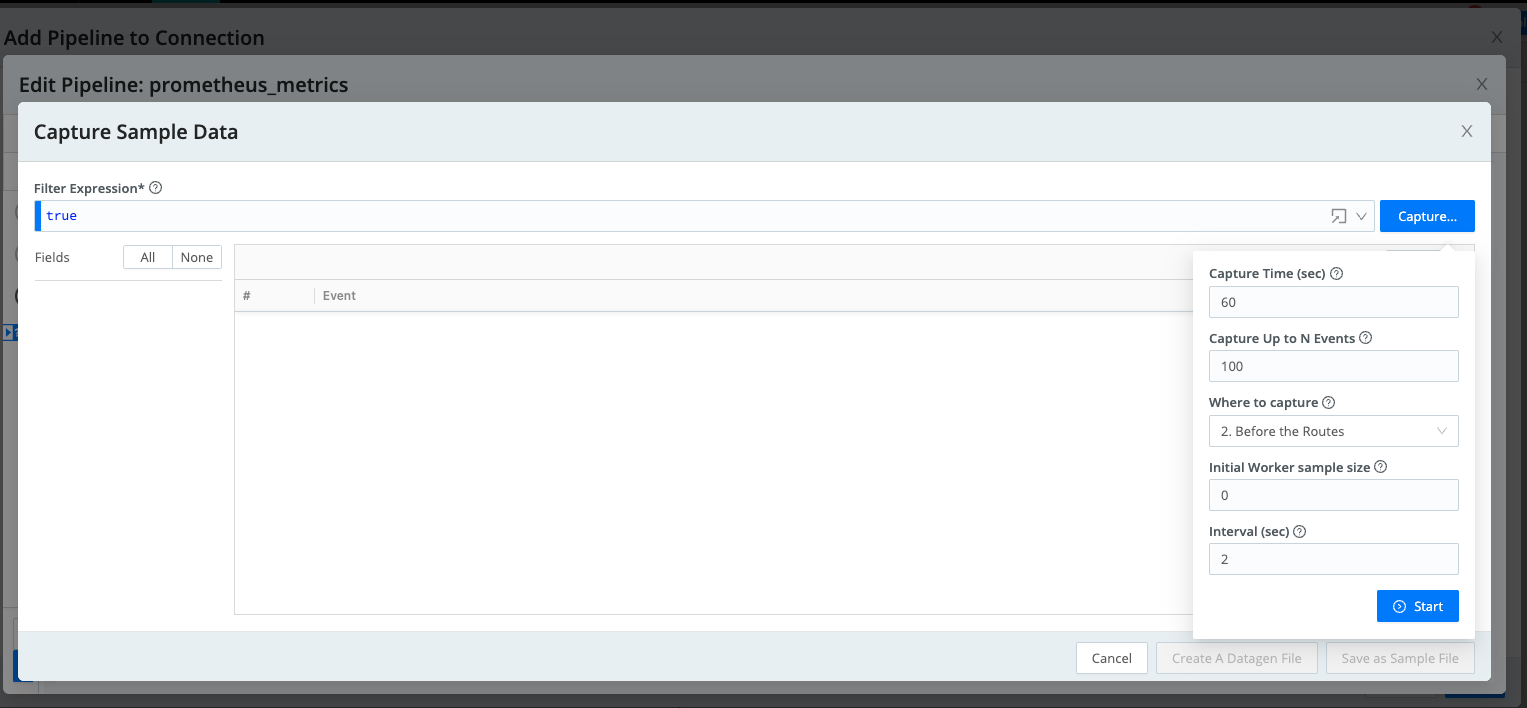
Step 3: Set Sample Data Parameters
Capture sample data to provide the base data model for creating and testing the Sampling function.
Sample Data -> Capture Data -> Capture -> Modify Capture Time (sec), Capture up to N Events -> Start
Capture Time (sec) = 60 ; Capture Up to N Events = 100
Modify the Capture Time (sec), and the Capture Up to N Events based on how large you want the sample data model.
Pro TIP: If you receive a “request entity too large” you can adjust the default sample size, 256K, to a maximum size of 3 MB. Learn more about controlling the sample size on Cribl Edge.
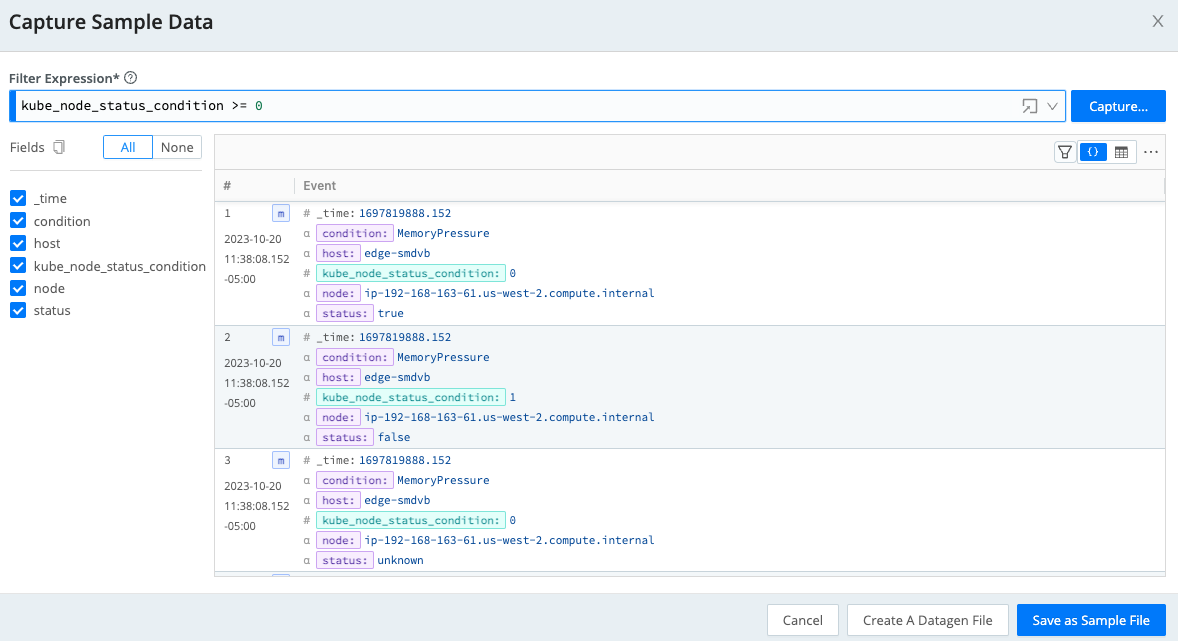
Step 4: Validate, Filter Sample Data
Now that you have sample data time and event parameters set, select fields to work with. This is a great way to hone in on only the fields you are interested in sampling.
Filter Expression -> Fields -> Save as a Sample File
Add Filter Expression: ‘kube_node_status_condition >= 0’
To focus on node status fields, you can filter for the presence of a field name in the event by adding ‘kube_node_status_condition >= 0' to the Filter Expression. This will create a sample with only logs that contain ‘kube_node_status_condition’.
If you find that you need more data to work with, based on the Filter Expression, adjust your time and event parameters.
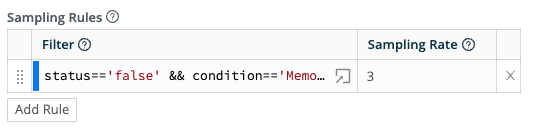
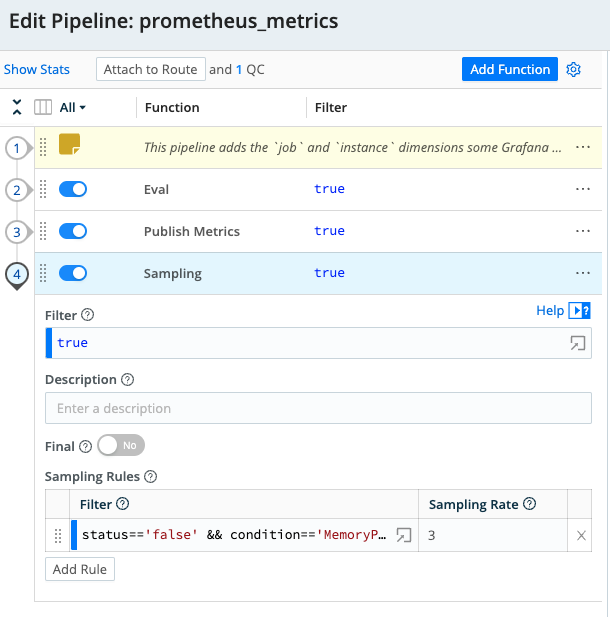
Step 5: Add Sample Rules
By adding Sampling Rules you can apply specific criteria while maintaining the desired level of fidelity for metrics.
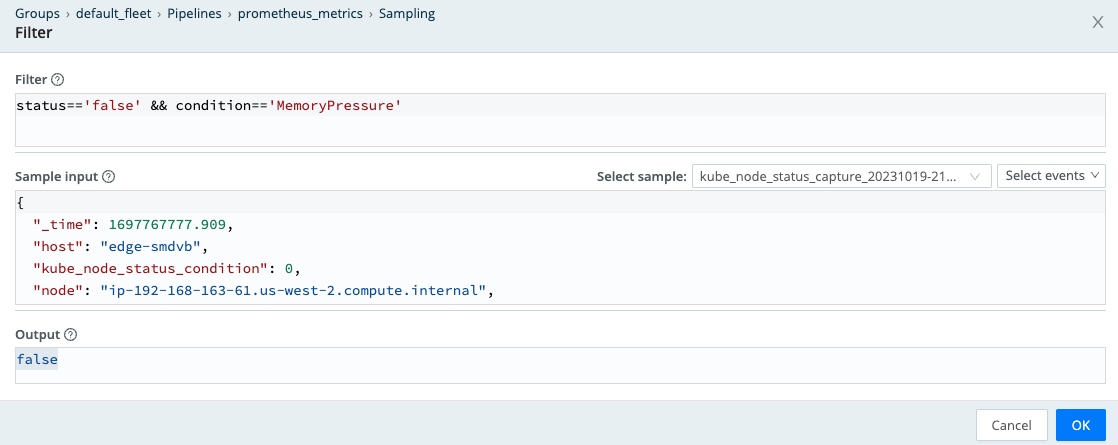
Select -> Add Rule → Advanced Mode
Add a rule that will sample the less critical information, at a rate that will still power dashboards and alerting at the destination.
Filter: status== ‘false’ && condition== ‘MemoryPressure’
Add a rule that will sample the less critical information, at a rate that will still power dashboards and alerting at the destination.
The sample rate of 3 was selected due to the high volume of metrics ingested from the source. This will output ⅓ of the metrics for node status where ‘MemoryPressure’ is ‘false’, indicating there is NOT memory pressure on the node memory. For this sample, a rate of 3 reduces the output of less critical metrics while still powering and alerts.
ProTIP: You can increase or decrease the sampling rate based on the confidence you have in the system performance and how closely it should be monitored. For example, if there is a cluster that has been performing well, and no changes have been made recently, you may feel comfortable increasing this sampling rate. However, if there have been changes made to the cluster, or there are performance issues to be monitored more closely, decreasing the sampling rate may be appropriate.
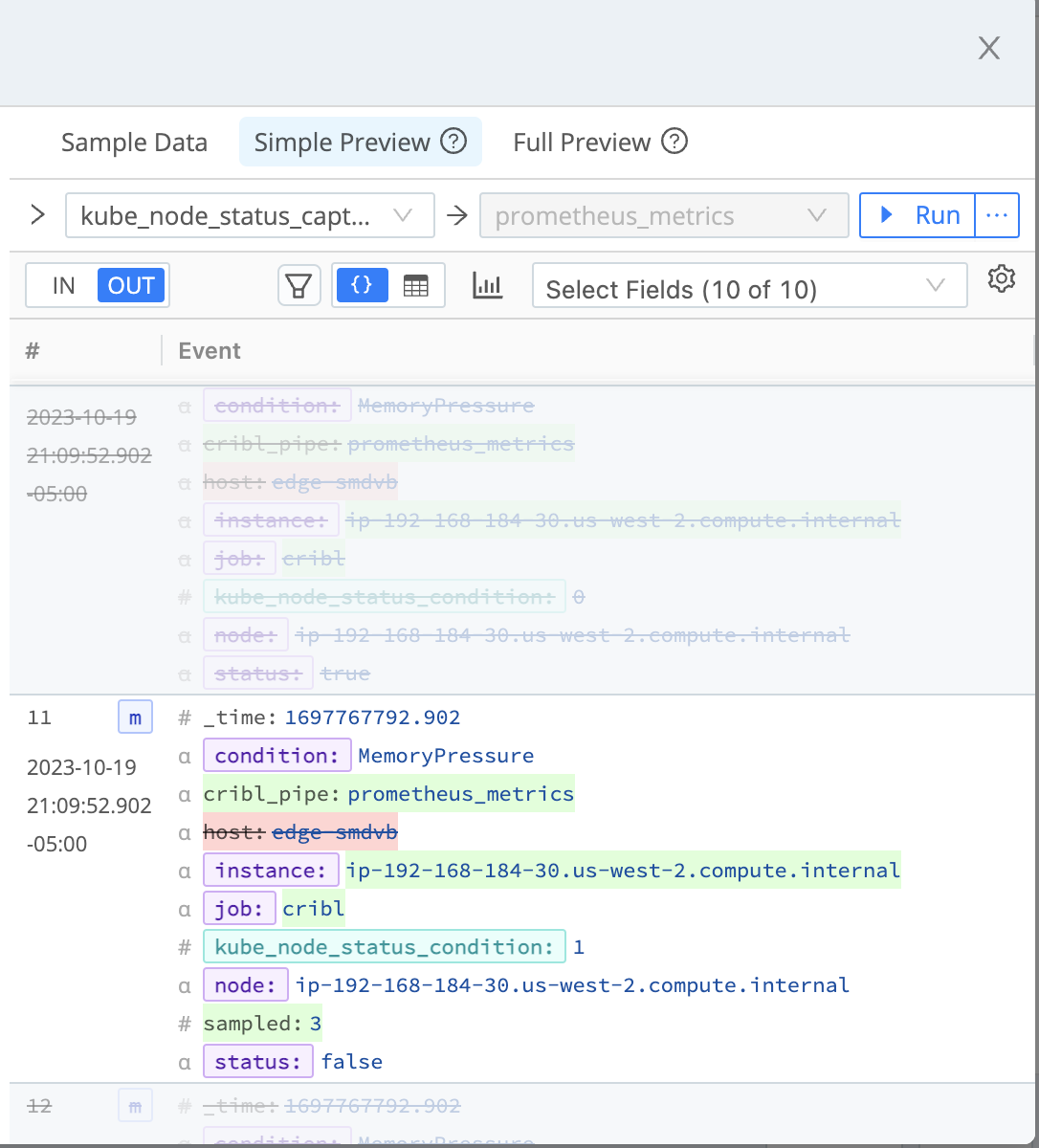
Step 6: Preview changes
Run the sample data model through the pipeline and see the Sampling function in action.
Sample Data -> Select File Name - > Run
Take a closer look.
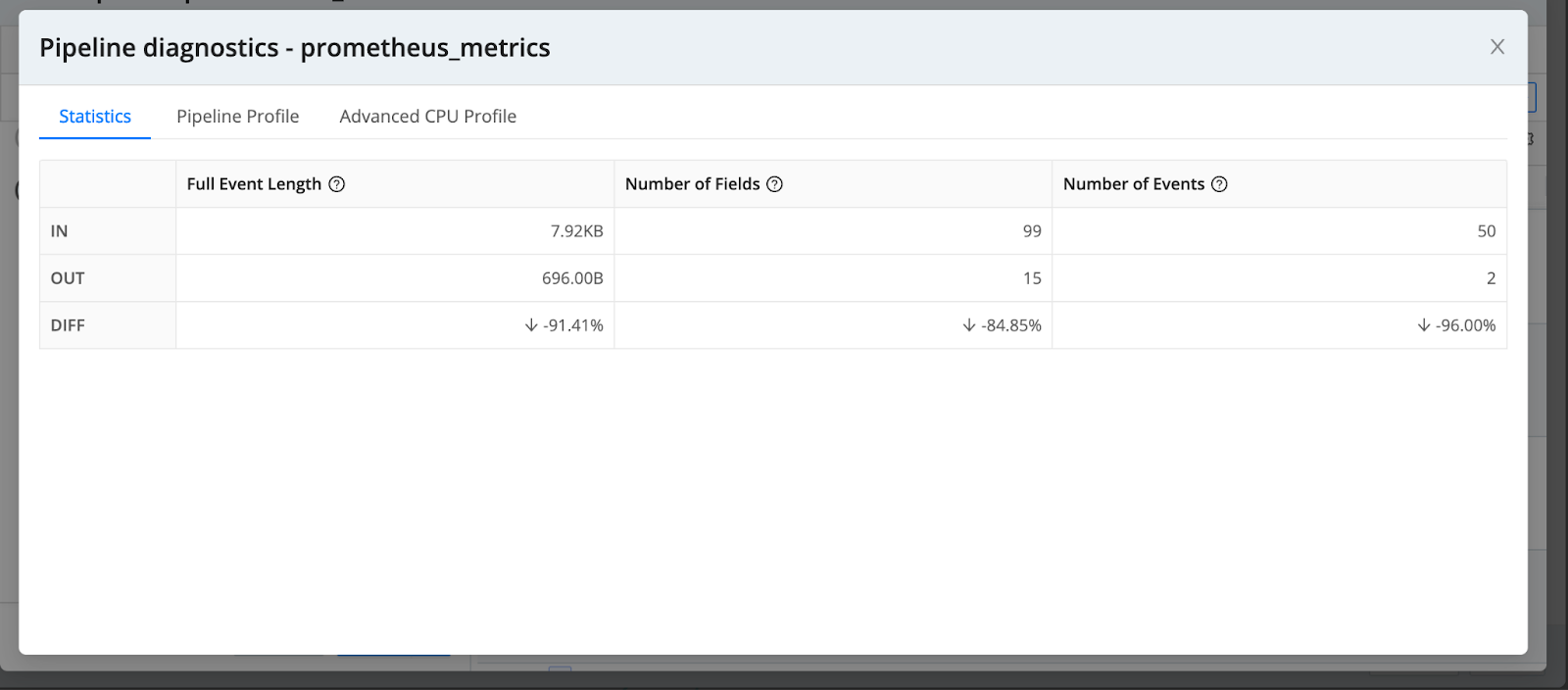
Preview -> Simple -> Pipeline Diagnostics
Step 7: Modify and Test the Sample Data Model
Further modify the output through your pipeline by adjusting the sampling rate, and/or adding additional filters to achieve the desired reduction of data, while not missing critical information.
Choose to leave the Filter Expression set to ‘True’ to allow all data to pass through, or add Filter Expressions to specify relevant events. In the case of node status conditions, you do not want to limit the output to only events that contain ‘kube_node_status_condition >= 0’, as you did with the sample data. However, you may want to add more rules to filter other types of metrics to achieve the best visibility into other conditions.
Example:
status== ‘false’ && condition== ‘DiskPressure’
status== ‘false’ && condition== ‘PIDPressure’
Step 8: Check Your Work!
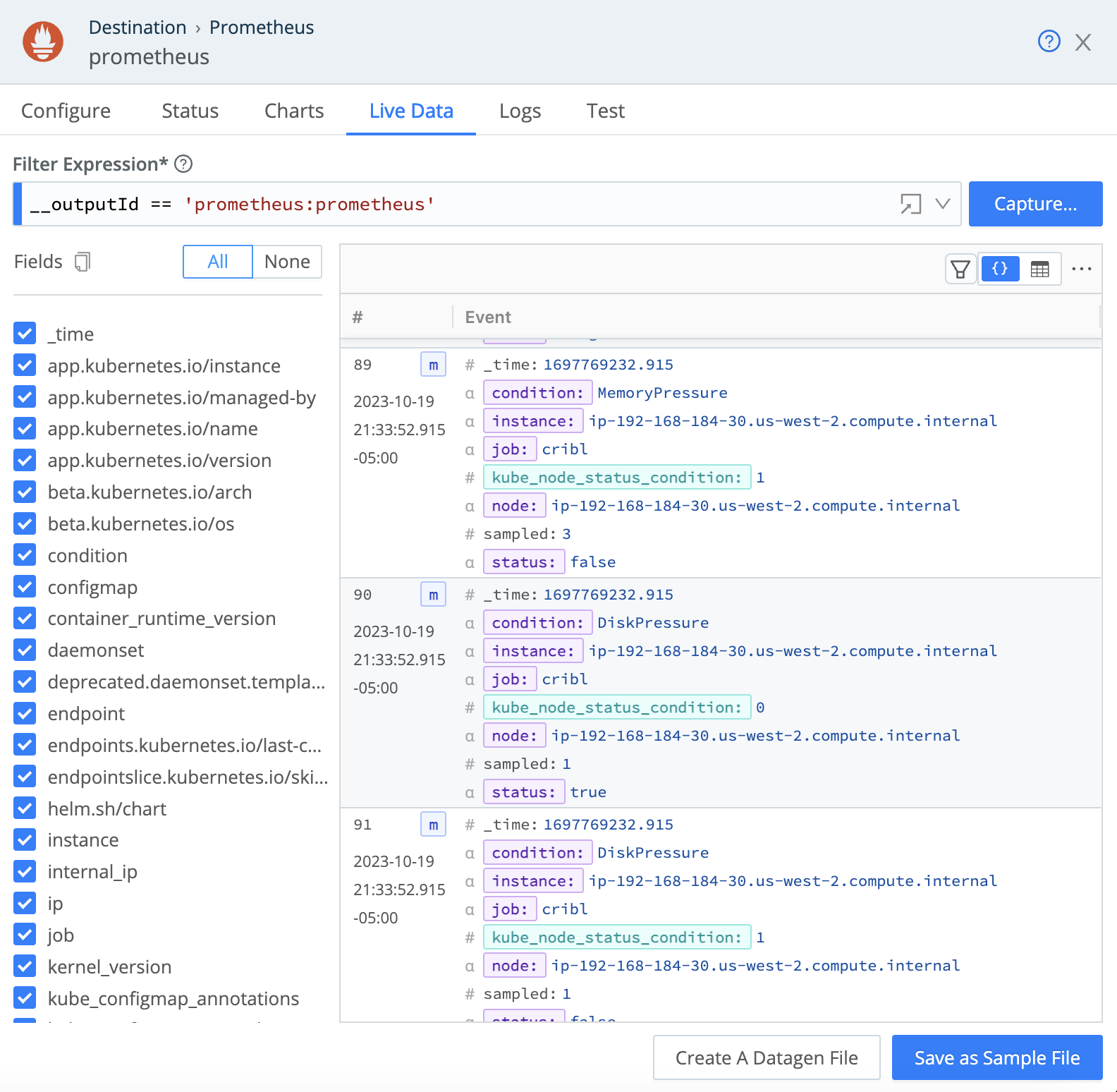
Validate the output of your pipeline by capturing live data at the destination.
Destination -> Capture -> Show Internal Fields
Wrap Up!
This same process can be used to optimize many other aspects of metrics related to Kubernetes, while still maintaining visibility into the system state as a whole. You can use the sampling technique for optimization purposes, testing purposes, etc. To learn more about Optimization techniques, check out the Cribl Guide to Tools Optimization.