At Cribl, we love optimization. You may have come across some of our reduction figures: 50% or even 80%. These numbers may seem hard to believe, leaving you wondering, “How can we achieve these results?” The Pack is an excellent framework to begin with. However, you'll need to adjust these configurations and make some customizations to tailor it to your particular use case and optimize reduction. Let's go through the process step by step.
Use-case: Achieve optimization by leveraging native functionality using out-of-the-box Packs. The CrowdStrike FDR Pack is specifically designed to manage the top 50 CrowdStrike FDR event types. Additionally, there are over 400 different FDR event types you can optimize!
Step 1: Find and Download the Right Cribl Pack
Download packs from the Dispensary or directly from Cribl Stream in version 3.4+.
To download directly from within Cribl, go to Manage → Processing → Add Pack.
In this example, you will be working with the Crowdstrike FDR Pack. This pack is a great one to start with since it provides detailed information on how to work with Crowdstrike FDR data.
Step 2: Get to Know Your Pack
The best way to understand your Pack is to start with the ReadMe.
Select the Cribl Pack → Pack Settings.
The CrowdStrike ReadMe is a comprehensive document that includes general instructions, a data processing pipeline visualization, an explanation of why the pack exists, and how you can benefit from leveraging the pack.
For example, CrowdStrike FDR logs are rich with fields and values, but a lot of the data could be considered noise and unnecessary for security monitoring. The Pack addresses dropping, removing, aggregating, sampling, and more, to achieve up to 80% optimization. Make note of this area since you can use these techniques later.
Pro TIP: The CrowdStrike FDR Pack can also be used for enrichment purposes, but we’re focused on reduction for this guide.
Step 3: Check out the Pipelines
Now that you understand what the Pack is supposed to do, let’s see how it accomplishes these tasks.
Routes → (4-6) SIEM Routes → CrowdStrike_Streaming_Events
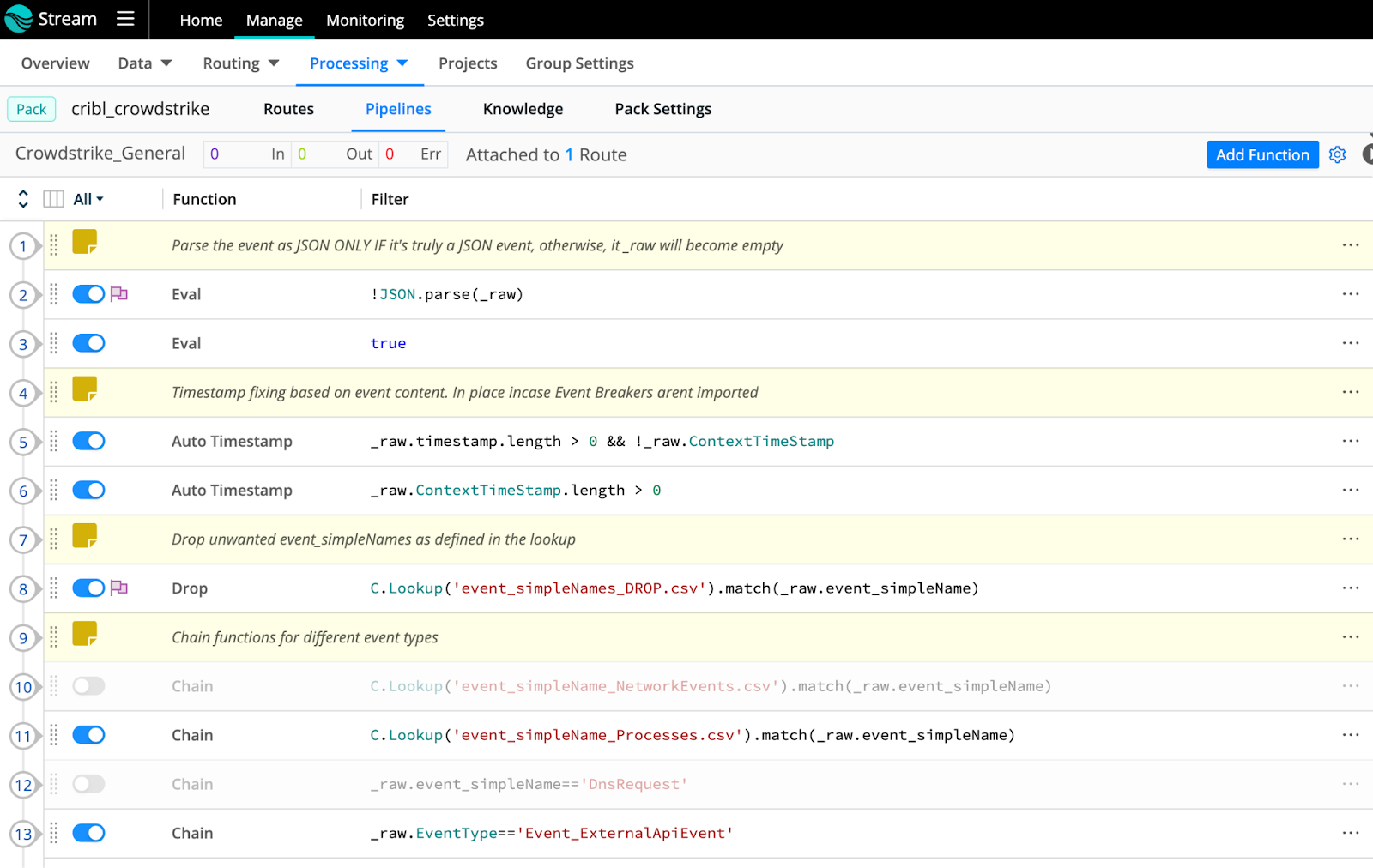
In the capture above, see the general processing of Crowdstrike FDR events in Pipelines 1-7. Each pipeline can be expanded by clicking in the Function field; pipelines can also be reordered by dragging up or down the set. Pipeline 8 is where the Pack begins matching on selected events from the lookup file ‘event_simpleNames_DROP.csv’. You can also find most of the event_simpleNames contained within your log, in ‘event_simpleName_ALL.csv’.
Step 4: Locate and Explore the Lookup File
This is where you see all the event types that will be dropped, and add more as needed. When adding rows, it's a great idea to leave comments on why/when that specific row was added for future reference.
Knowledge → event_simple Name_Files
When adding rows, it's a great idea to leave comments on why/when that specific row was added for future reference. Example:
Step 5: Understand the Data and Volume of the Log Source
Since the focus is on reduction, you need to know how much data, and of what kind, the source is producing. In this step, use your data storage product of choice to create a temporary location for duplicate logs. For example, create a temporary Splunk index or a new repository in LogScale.
This will be a test location that avoids co-mingling logs that may be reduced with active, working logs. Taking this approach it’s easy to focus on high-volume events and identify candidates for reduction.
Step 6: Assemble Your Herd and identify!
Identify and assemble your application administrators, security engineers, compliance experts and other data consumers or stakeholders.
Team collaboration is critical to accurate and swift reduction! Beyond preparing your stakeholders for changes to their data, these are the people who know their data best.
Identify business cases and the logs needed to support, i.e.:
- Event data that powers security use cases or monitoring dashboards
- Data required for industry compliance or oversight
- Metrics and performance monitoring data
Add events to your lookup that:
- Duplicate information from other primary sources
- Have no data consumer or stakeholder
- Are missing fields or values needed to drive search results and dashboard views
- Are only Informational or debug event data with limited practical application
Since you have learned a bit about how our Cribl CrowdStrike Pack works, let's focus on adding to event_simpleNames_DROP.csv based on the criteria your team has identified. In real-time, you can review log output by volume and address the correct stakeholders regarding what information can be dropped.
This may also be a great time to discuss whether sending a full-fidelity copy of your data to a data lake is the right choice for your organization. Sending only the data necessary for security tools’ reporting and analysis is another way to achieve reduction and increase the fidelity of data sent to your destinations. Find out more in Cribl's Compliance Playbook.
Step 7: Wash, Rinse and Repeat
Steps 3 - 6 can be repeated to continue to customize the Pack to your business needs by adding to existing lookup tables for fast reduction. This process may not be able to be completed in a single session. Expect to convene your Herd between 5-10 times as adjustments are needed.
Step 8: Go beyond the Pack
Leveraging lookup files and adding to the native functionality of the Pack is a fast and easy way to achieve reduction. Take reduction further by getting more granular, moving beyond whole events to individual fields:
Possible areas for reduction:
- Remove null field values from your events
- Removed fields that contain the same data
- Aggregate logs into metrics
- Identify and aggregate events that are similar to other sources
- Identify events that are normal, but could provide insight into problems; Aggregate these by status, URI, or host
Functions to explore:
Once you have achieved your desired reduction, and your stakeholders are satisfied, send your data to production and get rid of the test data repository.
Wrap Up!
Beyond the obvious cost savings, like licensing and infrastructure costs associated with data reduction, there is the added benefit of optimizing tool performance. Check out our Tools Optimization Guide to learn more.
Find out more about the CrowdStrike Pack here, straight from the goat’s mouth here!