Are you suffering from fear of missing out (FOMO)? It is not uncommon for log outputs to change with vendor updates or internal administrative changes. Data that is parsed incorrectly, or not at all, can lead to missing events in your security and analytic tools. While log format changes are inevitable, Cribl Stream can significantly reduce, or even eliminate, the impact of missed events in your organization. With Stream’s native functionality, you can easily create a process for validating and bifurcating data that does not meet validation criteria. These events can be directed to a designated review repository for further review, while the rest of the data moves to the destination of your choice.
Use-Case: Create a process to validate whether log output is in an intelligible format for the destination. Use Cribl’s schema library as a framework to validate JSON data post-parsing. If the data does not pass validation, send it to a custom logging repository where it can be reviewed.
Step 1: Generate Data for the Source and Configure the Destinations
First, make sure you have the JSON source and destination of choice configured.
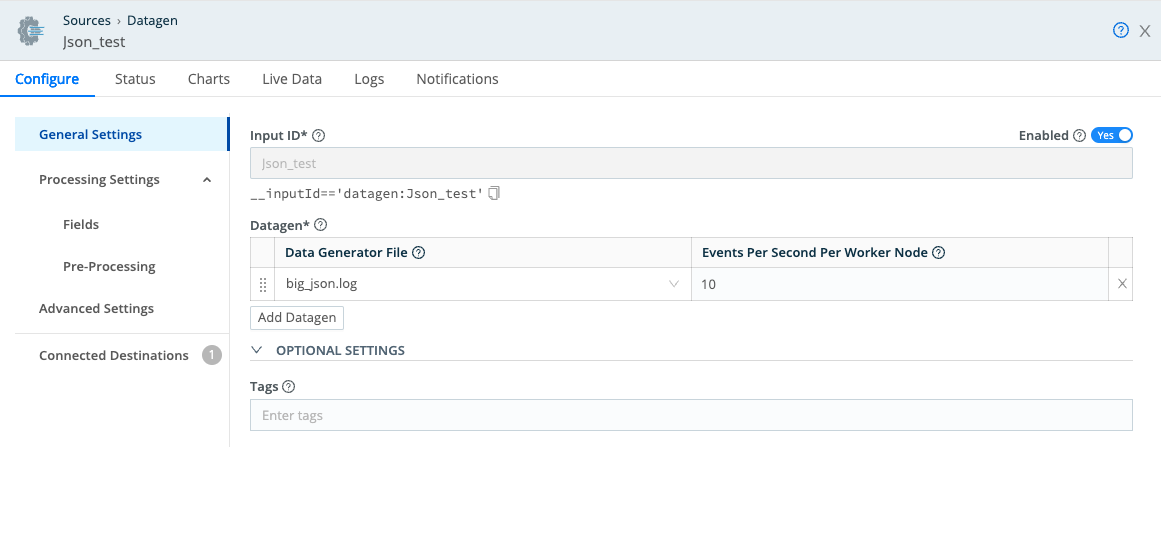
Manage -> Routing -> Quick Connect -> Add Source -> Datagen
In this example, use Quick Connect and Cribl’s Datagen Source configured with: ‘big_json.log’.
Step 2: Configure Destinations and Output Router
For this process, configure two destinations: One destination for the events that pass validation, like your SIEM, and a second for the review repository.
For the review repository, it is recommended to keep a short retention period (ex. 5-10 days) and that it is reviewed frequently. Find out more about configuring destinations in docs.
Next, configure the Output Router. This feature will be used later in the process diverting output to the correct destination based on results from the validation pipeline.
Add Destination -> Filter Destinations -> Output Router
Enter an Output Router Name and save it. You will return to configure the router in a later step.
Next, make a connection by clicking the plus icon on the Source and dragging to the Destination.
Source -> Destination -> Passthrough
Since you are working with sample data, the source is Datagen and the destination is Output Router. In the configuration pop up select pass through, you will configure the pipeline in the next step.
Step 3: Create Your Validation Pipeline
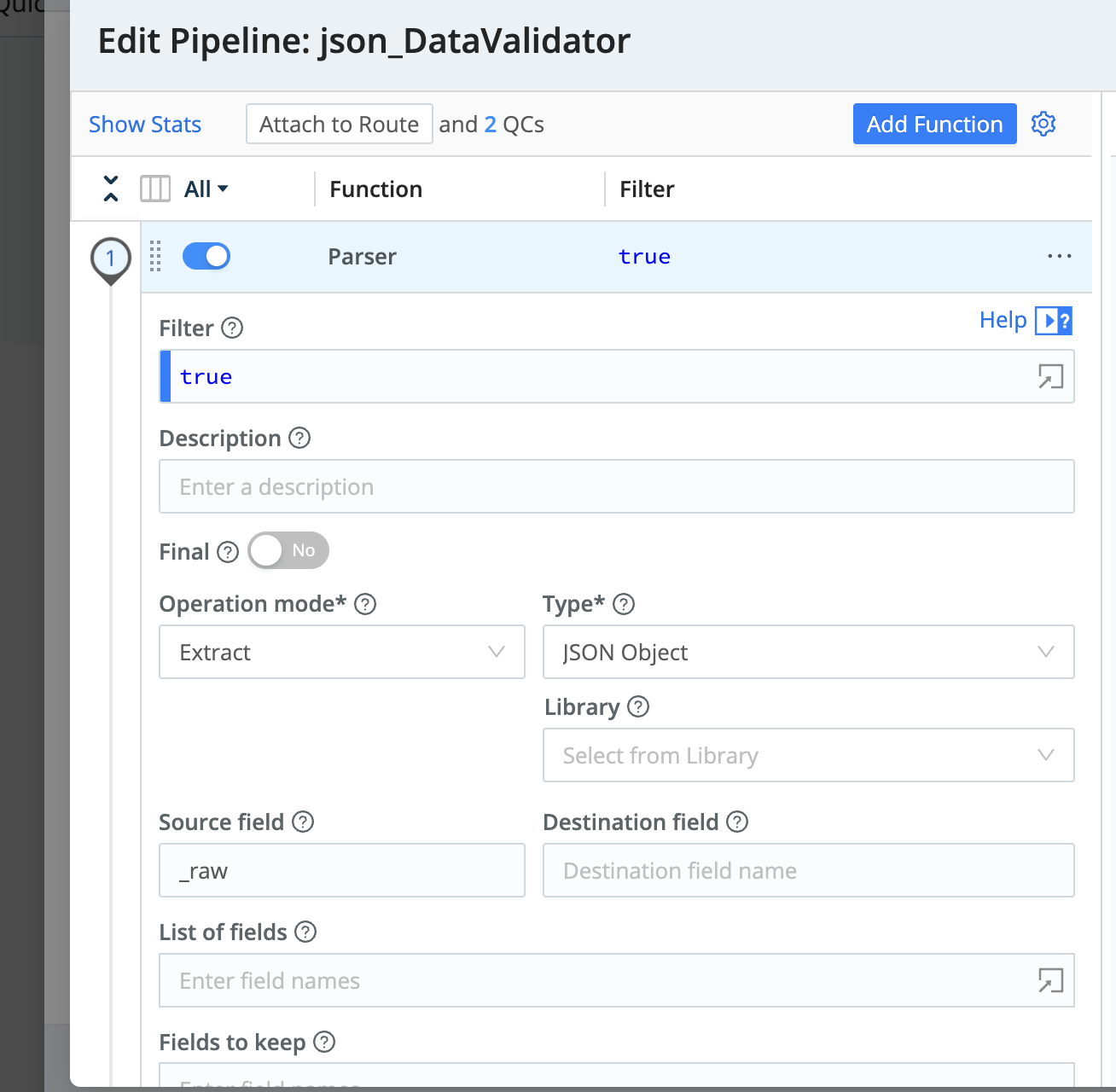
Create a route between the source and destination. In the QuickConnect pipeline you will add:
- Parser Function
- Eval Function
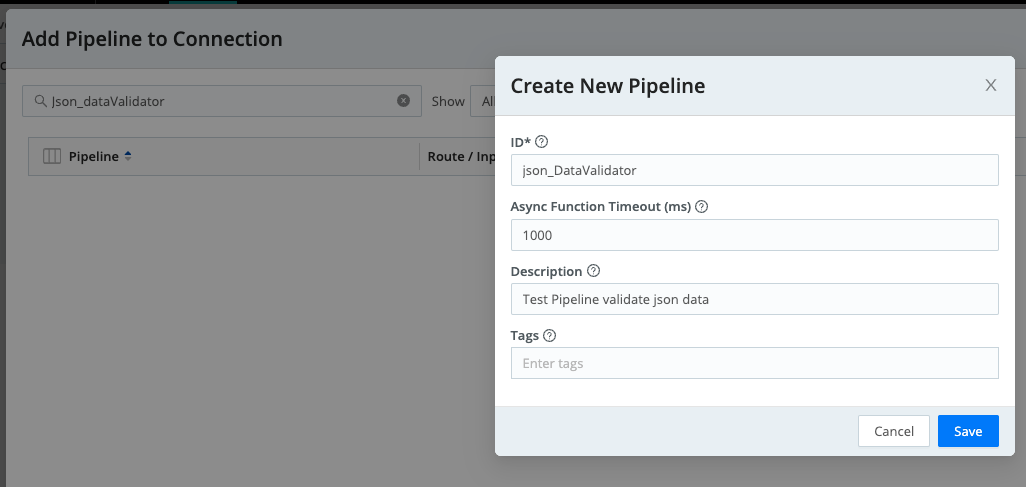
Select the Route -> Pipeline ->Add Pipeline to Connection -> Add Pipeline
Since you are working with Datagen it's ok to keep this step very simple. Leaving the ‘List of fields’ blank allows the Parser function to auto generate a list of fields for you! You will return to configure ‘Eval’ later.
Step 4: Create JSON Validation Schema
Now that a pipeline is established, create the JSON Schema based on the fields and values your security and analysis tools are expecting.
Processing > Knowledge > Schemas -> New Schema
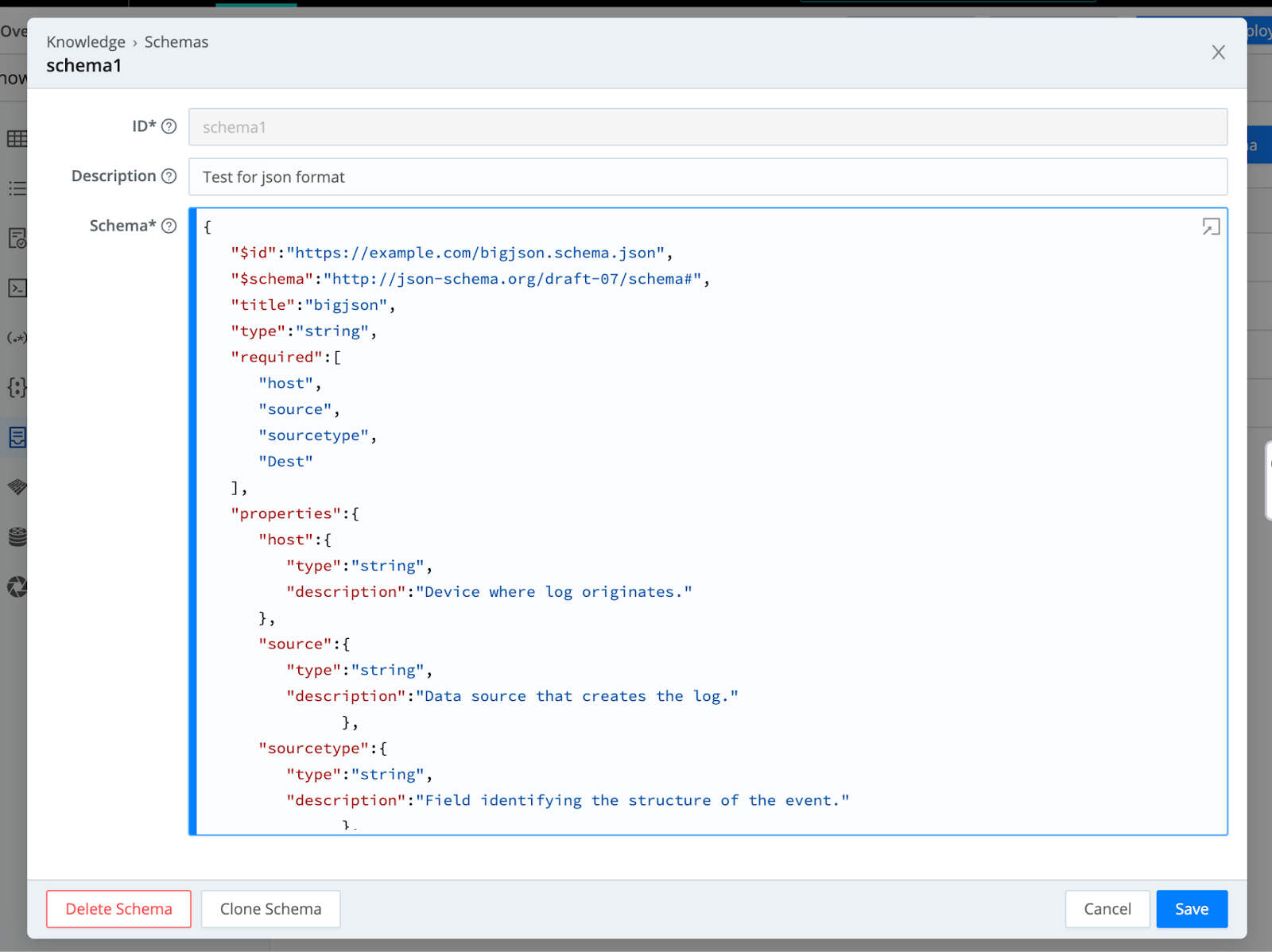
Start with the below JSON and save ID* as ‘schema1’.
{
"$id":"https://example.com/bigjson.schema.json",
"$schema":"http://json-schema.org/draft-07/schema#",
"title":"bigjson",
"type":"string",
"required":[
"host",
"source",
"sourcetype",
"Dest"
],
"properties":{
"host":{
"type":"string",
"description":"Device where log originates."
},
"source":{
"type":"string",
"description":"Data source that creates the log."
},
"sourcetype":{
"type":"string",
"description":"Field identifying the structure of the event."
},
"Dest":{
"type":"string",
"description":"Endpoint for the intended message."
}
}
}
The JSON schema contains the fields host, source, sourcetype and Dest, as string fields. While this is a simple validation, complexity can be added when/where necessary. For example, you can use the schema to ensure that host equals a specific value or constrain fields with integer values within a specific range.
Step 5: Update Eval Function to Validate Data
Return to the pipeline and update the Eval Function to include the JSON Schema you just created.
Manage ->Routing -> Quick Connect -> Pipeline -> Eval
Including a double underscore in the ‘Name’ field (__isvalid) enriches the event with a metadata field. This is an internal field that will not be passed on to your destination but can be used later to bifurcate your data.
For the Value Expression reference ‘schema1’ and add host as the value. You are validating that ‘host’ is present and contains a string value. You can add any of the fields (source, sourcetype, dest) here to be validated.
Step 6: Test the output of your pipeline
Capture sample data to view to test the results of the Pipeline.
Sample Data -> Capture Data -> Capture ->Start -> Save as Sample File -> Simple Preview
By default, internal fields are not shown in the output.
Settings -> Show Internal Fields
In the two logs from the sample, you can see ‘__isvalid:true’. These logs have passed the validation test. Now test ‘Dest’
Eval -> Add Field
Save the changes that have been made to the Eval function. Pivot to the Simple Preview and re-run the Data Capture File against the sample.
Since the field ‘Dest’ has been added to a validator, you will now get ‘__isvalid: false’ because the Dest field does not exist in our bigjson.log file.
Pro TIP: While this pipeline is validating data in the route, validation could also be done at the source using a pre-processing pipeline.
Step 7: Send Data to the Right Destination
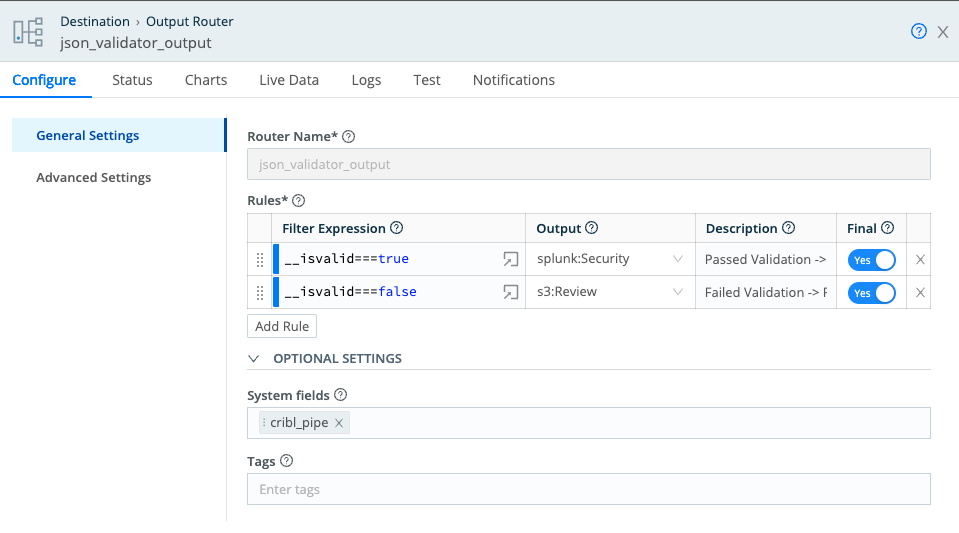
Return to the Output Router and add the Filter Expression to direct data to the desired location.
Destinations -> Output Router ->Rules -> Filter Expression
Events where the ‘__isvalid:true’ are sent to security and analytics tools. Events where the ‘__isvalid:false’ are sent to a separate repository for review.
Step 8: Check Your Work!
You can validate the output of your pipeline by capturing live data at the destination.
Destination -> Capture -> Show Internal Fields
In the above example, you can see that ‘__isvalid: false’ is sent to the ‘__outputId: s3:Review’ which is exactly the result we were expecting.
Wrap Up!
This framework is a great way to ensure that security and analytic destinations receive data in a format that is recognized. You can include as many or as few fields as needed to validate the data. This framework can even be extended to similar use-cases like segmenting data by host, source, or sourcetype to alternate destinations.