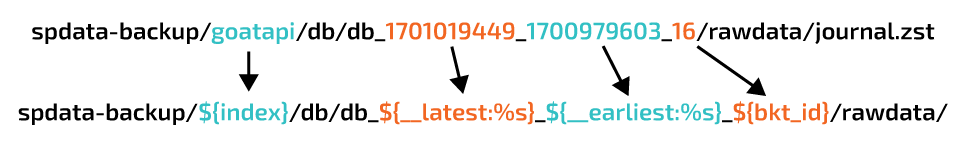IT and Security administrators face a challenging balance: they need to store increasing amounts of data for compliance and auditing, yet must also manage their license and storage costs effectively. To navigate this, many Splunk administrators have developed strategies that involve swiftly rolling data from searchable buckets to long term, inexpensive solutions like Amazon S3. This transfer is often achieved through bespoke backup systems or Splunk Cloud's Dynamic Data Self-Storage (DDSS) feature.
However, while this approach satisfies data retention demands, reintegrating this data back into Splunk for analysis can be a complex and tedious process. To make the data searchable again, admins must first establish a new index on an indexer, transfer the stored data buckets to a "thawed" directory within the index, and then execute a "rebuild" command to reinstate the data. Only after these steps, can we determine whether the restored data even encompasses all the necessary events for the investigation. If not, get ready to start from square one.
A microwave for your frozen data dinner.
Cribl Search allows you to query this archived data in-place, giving you quick, actionable insights into your stored Splunk data. User's can create reports, alerts and dashboards without the need to ingest or even move it.
Beyond basic searching and reporting, Cribl Search enhances functionality by allowing search results to be sent through Cribl Stream and back into multiple destinations, not just Splunk. This comes in handy for cloud and tool migrations where you need to get Splunk data into Splunk Cloud, or another tool such as Azure Sentinel. Allowing you to transform, enrich and mask the results if needed.
Let's explore what this data looks like and how you can effortlessly search it.
The anatomy of a stored Splunk Bucket.
Cribl can search journal files created by Splunk when data is indexed.
Note: By default these are kept inside a series of subdirectories found in $SPLUNK_HOME/var/lib/splunk/<index_name>/ on Splunk Indexers, but can be defined in the Splunk GUI. You will need to check settings for your deployment.
When backing up Splunk files it's best to roll any hot buckets to warm before moving files to the datastore. This can be done using the roll-hot-buckets endpoint on the Indexer.
$SPLUNK_HOME/bin/splunk _internal call /data/indexes/<Index_name>/roll-hot-buckets -auth <admin_username>:<admin_password>
When these files are moved to storage the directory structure will look something like this:
We will use this information to define the path filter for our Search dataset later, but first we need to make the buckets stored in S3 available to Cribl Search.
Be aware that if you are moving historical data, you might have data that has rolled to cold or frozen buckets. By default, cold bucket data is found at $SPLUNK_HOME/var/lib/splunk/<index_name>/colddb/ on Indexers. Frozen data will only be stored if a path has been defined. You will need to check settings on your Splunk deployment to make sure that you are storing ALL available data.
I Got Your Hook-up: Adding a Data Provider
To use Cribl Search, you need to first have a Dataset Provider and a Dataset. Dataset Providers define where the data lives, and how to access it. Datasets define the data that needs to be queried.
For this example we will be using Amazon S3 as the Dataset Provider. But Azure Blob, Google Cloud Storage, or almost any data lake solution can be used. Cribl Search can also run federated searches across all your Dataset Providers, See this blog for more details.
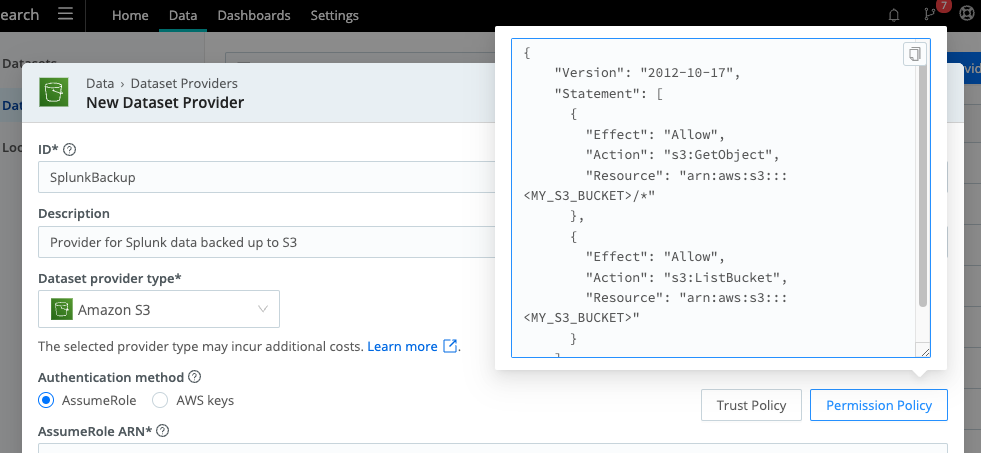
From the Cribl.Cloud home page, we click the "Explore" button for Cribl Search and then select Data > Dataset Providers > Create Provider. After entering an ID, Description and Selecting the Amazon S3 Provider type, buttons that expose templates for Trust and Permission Policies are provided.
Cribl allows users to enable the use of AWS Assume Role credentials to access S3 compatible stores. Assume Role enables one AWS identity to "assume" a role within another AWS account, gaining temporary security credentials for accessing AWS resources that have been made available to the role it has assumed. Since Cribl.Cloud is running on top of AWS, you can use the role it is running under to access a role in an external AWS S3 account.
There is also an option to use AWS Keys, but we will not use them in this example.
The provided templates simplify the process of creating the role and permissions required in your AWS account. Clicking on one of their buttons will open it in a window, allowing it to be copied.
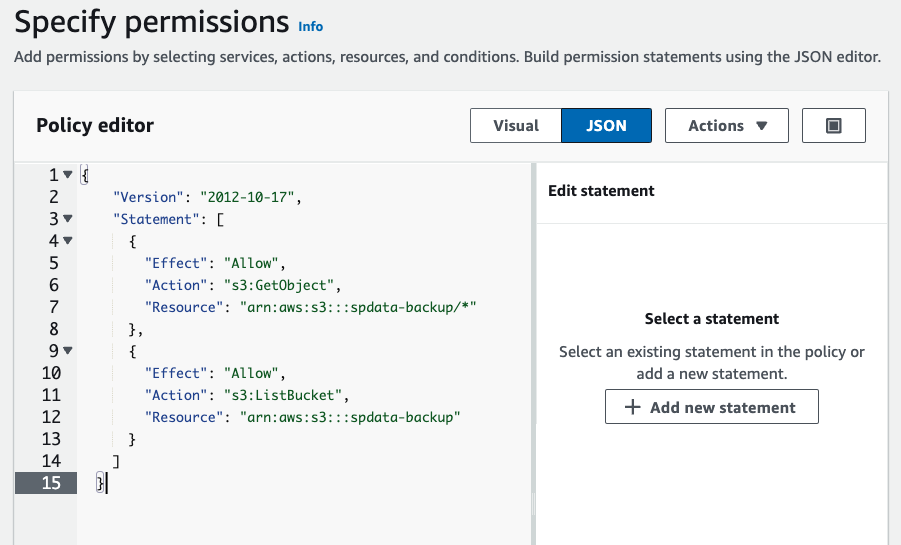
Setting up the policy first will simplify attaching it to the new role we will create later. Copy the template for the Permission Policy and navigate to the IAM Dashboard in your Amazon Web Services account. Under "Policies" click "Create Policy" and select "JSON" as the editor. Paste in the policy template you copied and replace the "<MY_S3_BUCKET>" instances with the name of the S3 bucket your data is stored in.
Click "Next", give the policy a name, and save it.
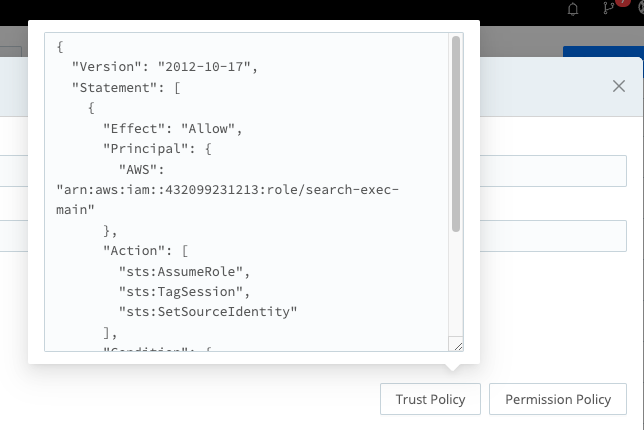
Returning to your Cribl.Cloud instance select the "Trust Policy" button, and copy the template.
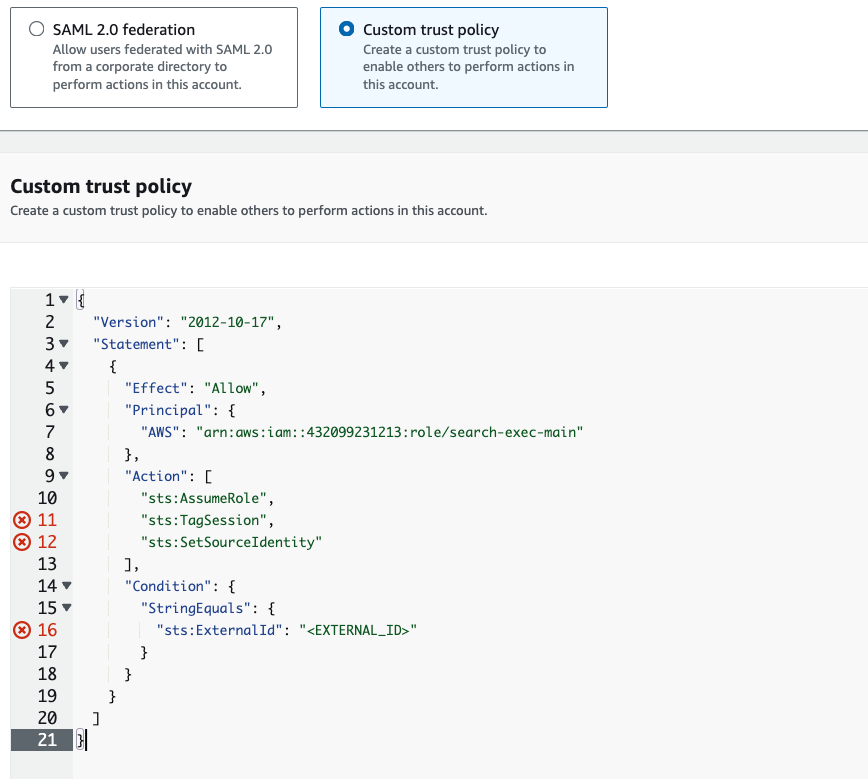
Navigate back to your AWS IAM Dashboard, select "Roles" and "Create Role". Select a Trusted entity type of "Custom Trust Policy" and paste in the example policy.
Notice the "<EXTERNAL_ID>" value. External IDs provide a unique identifier for the trust relationship between your AWS and Cribl.Cloud accounts. The External ID should be a unique and unpredictable string. After entering the External ID and clicking "Next", you will be asked to add permission policies to the role. Search for the policy you created, select it, and select "Next". Provide a Role name and Description then click "Create Role".
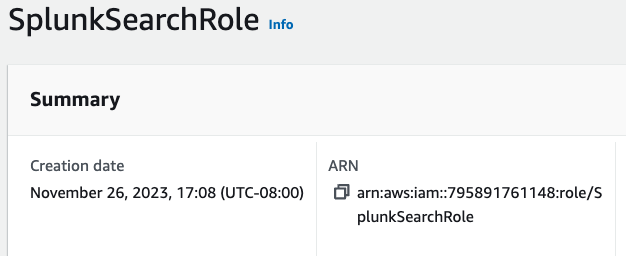
Click on your newly created role and copy the ARN for the role.
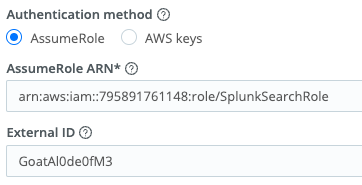
Return to Cribl.Cloud and enter the ARN and External ID you added to your trust policy before saving.
Put it on the Map: Adding a Dataset
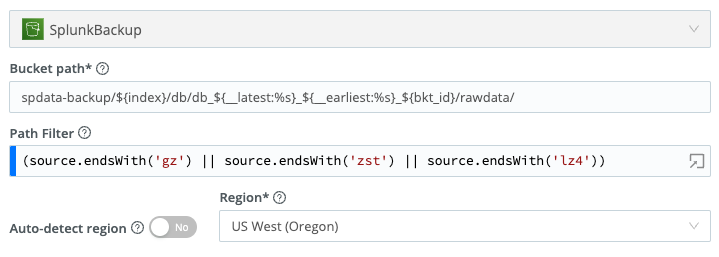
Next you need to set up the Dataset. Click "Datasets" and "Add Dataset" giving it an ID and description before selecting the Dataset Provider you created.
The Bucket Path field is very important. It tells Cribl how your data is segmented in your S3 bucket, and allows you to templatize the path so that it can be used in Search commands.
As an example, the path shared above can be templated to allow Search to query data by index, time and bucket id.
You can also filter the items in the bucket that can be searched. By entering in a filter expression of (source.endsWith('gz') || source.endsWith('zst') || source.endsWith('lz4')) only files ending in the correct archive formats will be available to Search. All pointer and metadata files will be ignored.
After saving the dataset, we’re ready to Search!
Eureka!: Searching Stored Data
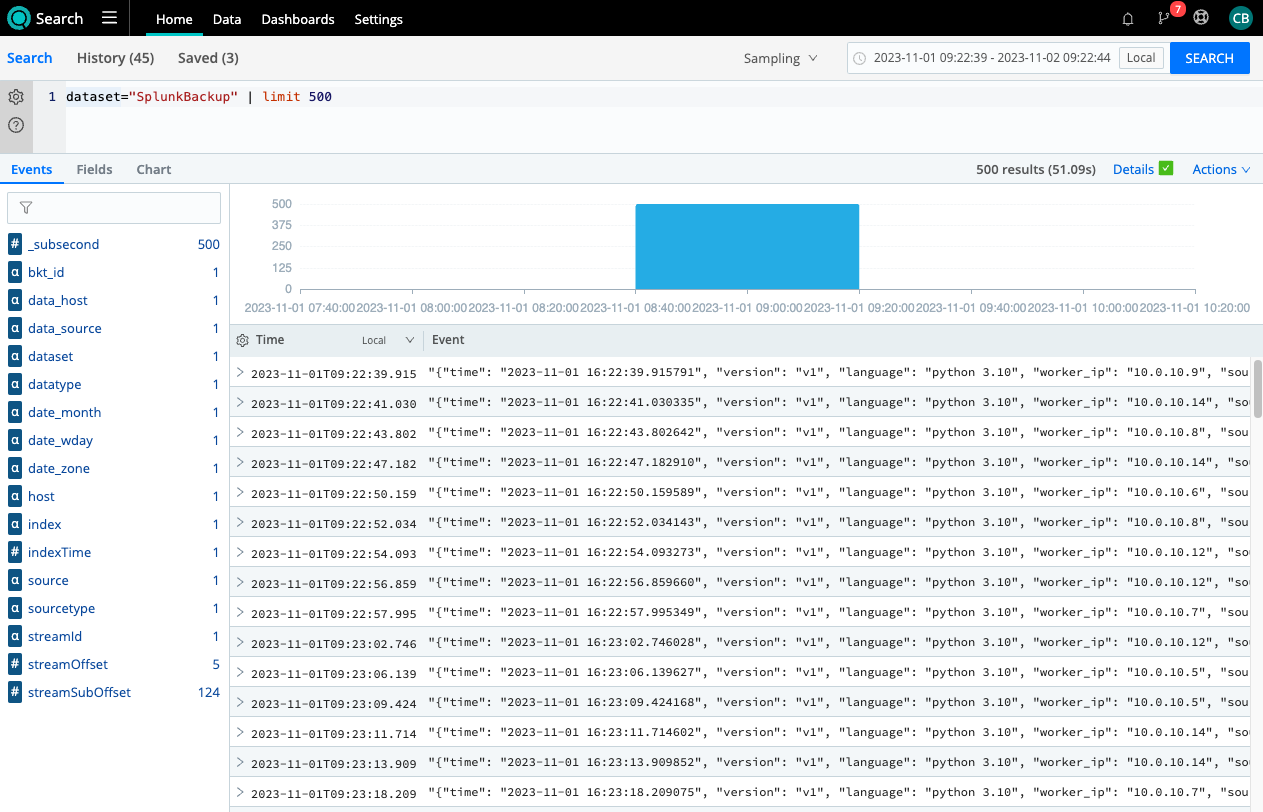
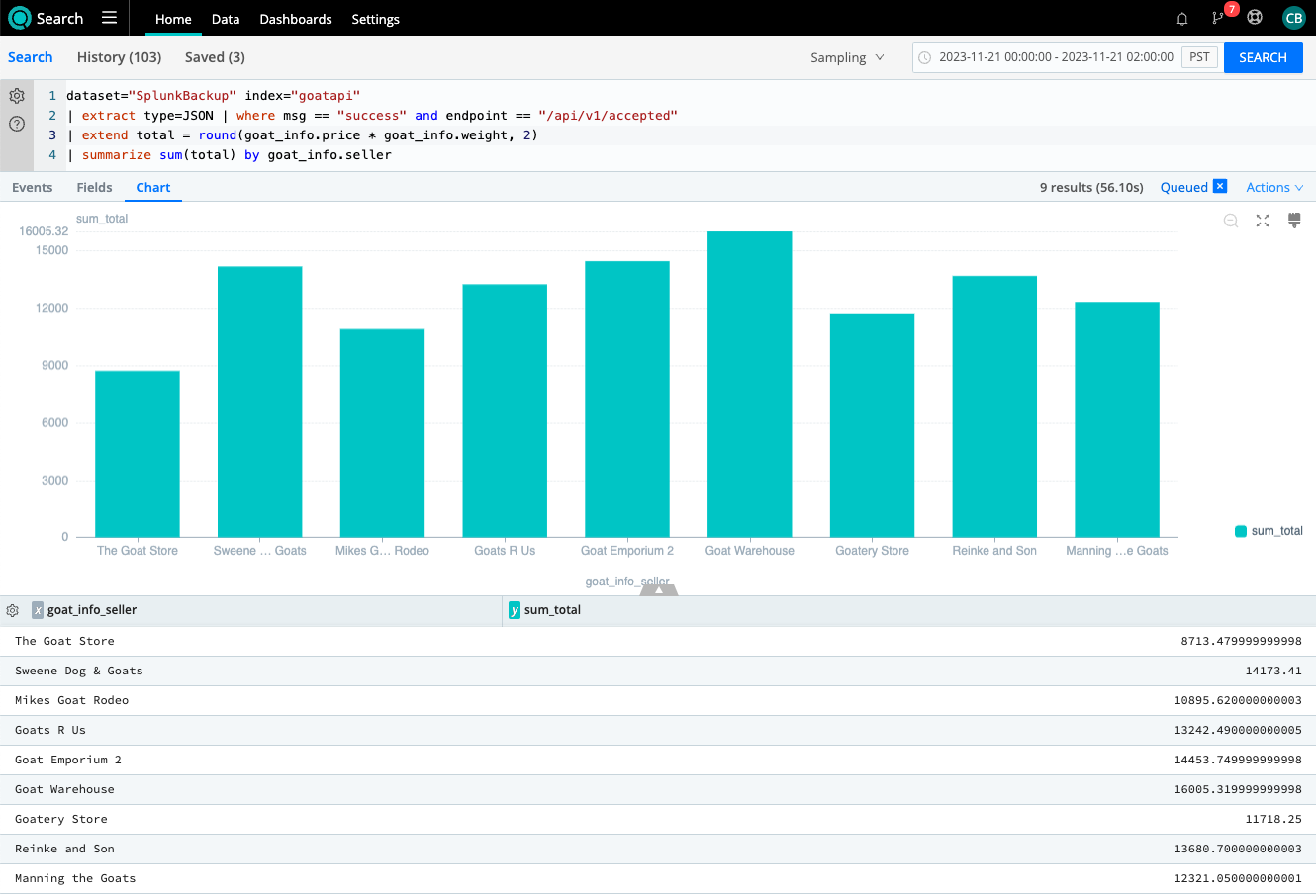
Returning to the Cribl Search home page, select the dataset and a time range, results are returned from the archived data. No need to unthaw, collect, move, or ingest data.
You are also not limited to only returning events, you can make the data actionable. Search allows you to create alerts, reports and dashboards based off of your data and searches.
As mentioned earlier, we can also send search results back through Cribl Stream, optimizing, enriching, and transforming data before routing to destinations. The send operator pushes events to a Cribl Stream Worker Group as a Cribl HTTP source. You can define what Cloud Worker Group will process the events using a "group" argument.
When using hybrid Worker Groups, a url can be used as the destination for the search results.
Let's Wrap this up!
As you can see, Cribl Search makes it easy to report on and onboard data long after it is removed from your Splunk deployment. Giving you quick access to the events you need, while saving you money on storage and infrastructure.